



Rychlost inference je klíčovým faktorem pro praktické využití velkých jazykových modelů (LLM). Určuje, jak rychle GPU dokáže zpracovat vstupní dotaz a vygenerovat odpověď.
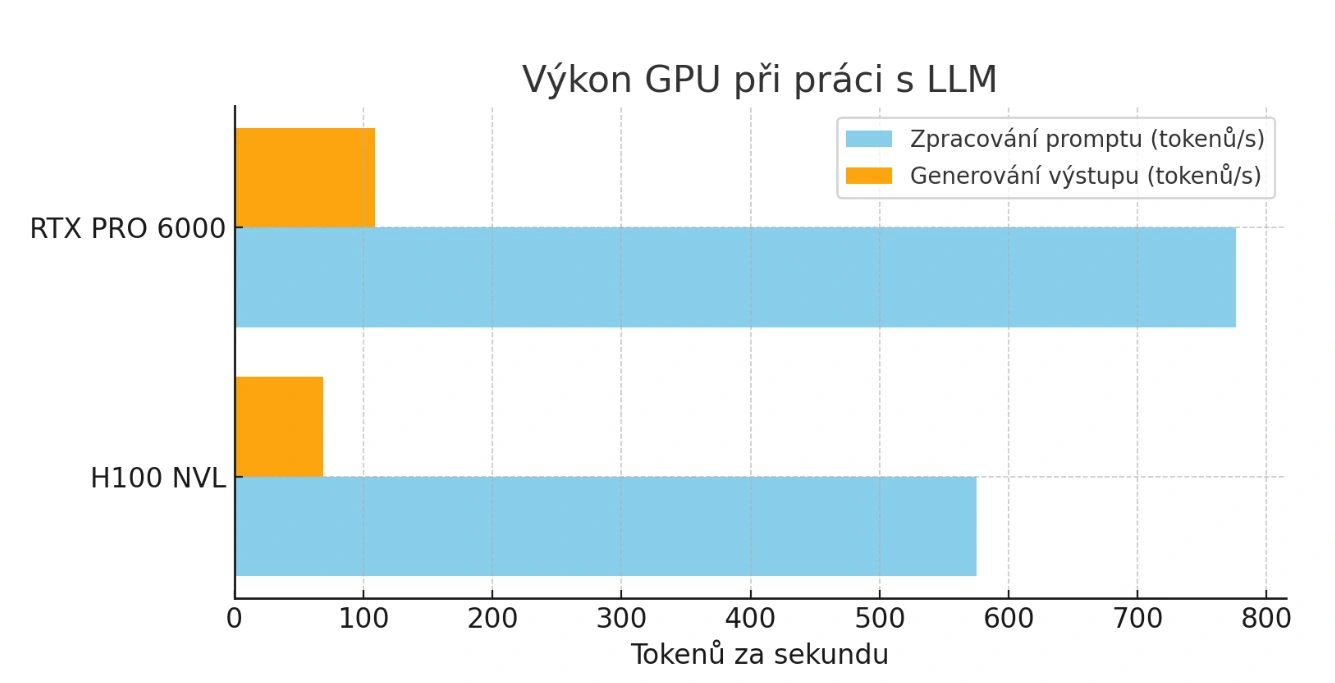
V testech zpracování vstupu (promptu), důležitém třeba pro RAG – retrieval-augmented generation, dosáhla H100 výkonu 575,5 tokenů/s. RTX PRO 6000 však překvapivě získala náskok s 776,2 tokeny/s, tedy o 35 % vyšší rychlostí. Odchylka v obou případech činila přibližně ± 10 %.
Při samotném generování výstupu se rozdíl ještě zvětšuje: PRO 6000 dosahuje 108,9 ± 4,3 tokenů/s, zatímco H100 jen 68,75 ± 1,64 tokenů/s - tedy až o 58 % rychlejší výstup.
Testy probíhaly s modelem gpt-oss: 120B (f7f8e2f8f4e0) z knihovny Ollama, spuštěné v OpenWebUI v0.6.18 a Ollama 0.11.2.
Každé měření probíhalo na samostatné instanci bez paralelního zatížení, takže výsledky přesně odrážejí výkon jednoho GPU v reálných podmínkách.
Přesvědčte se sami o síle nejvýkonnější AI GPU na trhu.
Otestujte RTX PRO 6000 a plaťte až po vyzkoušení.

Rozdíl mezi oběma kartami je propastný i finančně. NVIDIA H100 NVL vychází zhruba na 1 milion Kč, takže jde o řešení určené převážně pro rozsáhlé datacentrové projekty.
Oproti tomu RTX PRO 6000 Blackwell stojí přibližně 250 000 Kč – tedy čtyřikrát méně. Navíc ji lze pronajmout přímo u nás na ZonerCloud.cz za pouhých 14 990 Kč měsíčně, což otevírá cestu i menším týmům nebo jednotlivcům.
Spotřeba PRO 6000 dosahuje až 600 W, zatímco H100 NVL se pohybuje mezi 350–400 W. Díky tomu, že PRO 6000 zvládne celý model držet v paměti, odpadá nutnost multi-GPU clusterů i složitého síťového propojení, což významně snižuje náklady.
| GPU | Pořizovací cena | Poměr cena/H100 | Možnost pronájmu | Spotřeba |
|---|---|---|---|---|
| H100 NVL | cca 1 000 000 Kč | 1× | není běžně dostupné pro menší týmy | 350–400 W |
| RTX PRO 6000 Blackwell | cca 250 000 Kč | 0,25× (4× levnější) | ZonerCloud: 14 990 Kč/měsíc | až 600 W |
| Parametr | Hodnota |
|---|---|
| Architektura | NVIDIA Blackwell |
| Paměť | 96 GB GDDR7 ECC |
| Šířka sběrnice | 512 bit |
| Propustnost paměti | ~1,8 TB/s |
| CUDA jádra | 24 064 |
| Tensor jádra | 5. generace (752 jednotek) |
| RT jádra | 4. generace (188 jednotek) |
| Výkon FP32 | ~125 TFLOPS |
| Výkon AI/TOPS | až 4 000 TOPS |
| Rozhraní | PCIe Gen 5 x16 |
| Spotřeba (max) | 600 W |
| Podpora MIG/dělení | 1×96 GB, 2×48 GB, 4×24 GB |
Díky této konfiguraci dokáže karta pojmout celý model gpt-oss 120B v jednom GPU bez nutnosti swapování nebo rozdělování dat.
| Aspekt | PRO 6000 Blackwell | H100 NVL |
|---|---|---|
| Paměť | 96 GB | 94 GB HBM3 |
| Propustnost paměti | ~1,8 TB/s | ~3,9 TB/s |
| Výkon AI/TOPS | 4 000 | ~3 341 |
| Spotřeba | až 600 W | 350-400 W |
| Efektivita na watt | nižší | vyšší |
| Infrastrukturní nároky | nízké, pracovní stanice | vysoké, datacentrum |
| Držení modelu ≥96 GB | ano | může být limitující |
| Komplexita clusteru | snadné | vyšší |
Z tabulky je patrné, že H100 má sice výhodu v efektivitě a propustnosti paměti, ale RTX PRO 6000 vítězí praktičností – celý model zvládne v jediném GPU bez nutnosti složité infrastruktury.
Přesvědčte se sami o síle nejvýkonnější AI GPU na trhu.
Otestujte RTX PRO 6000 a plaťte až po vyzkoušení.
NVIDIA RTX PRO 6000 Blackwell je novým lídrem pro běh a trénink rozsáhlých LLM modelů. Díky 96 GB VRAM udrží kompletní model v jedné kartě, což zjednodušuje nasazení, zrychluje odezvu a snižuje riziko chyb.
Oproti H100 NVL nabízí vyšší rychlost inference, rychlejší generování výstupu, nižší pořizovací náklady a možnost flexibilního pronájmu. H100 zůstává volbou pro masivní datacentra, ale pro praktické nasazení LLM je PRO 6000 jasným favoritem – a navíc cenově dostupným.
Pokud hledáte nejrychlejší a nejdostupnější způsob, jak spustit velké LLM modely, vyzkoušejte RTX PRO 6000 na ZonerCloud.cz. Získáte přístup k nejmodernějším GPU přímo v Česku, s minimální latencí a bez nutnosti vlastního datacentra.
Žádné vysoké vstupní náklady, žádné složité nastavení. Jen čistý výkon připravený okamžitě pro vaše projekty s umělou inteligencí.
Napište nám a my se Vám ozveme do 2 hodin během pracovní doby.

 čeština
čeština  slovenčina
slovenčina  english
english